机器学习的任务:从学术论文中学习数据预处理
作为工作中最关键的部分,数据预处理也是大多数数据科学家最耗时的项目,他们大约80%的时间都花在这上面。
这些任务有多重要?学习方法和技巧是什么?本文将聚焦于著名大学和研究团队关于不同培训数据主题的学术论文。主题包括人类注释者的重要性,如何在相对较短的时间内创建大数据集,以及如何安全地处理可能包含私有信息的训练数据。
1.人类注释者有多重要?
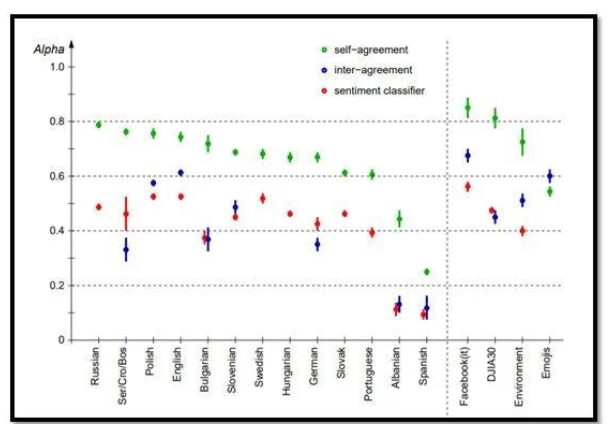
本文介绍了注释器质量如何极大地影响训练数据,进而影响模型精度的第一手信息。在这个情感分类项目中,约瑟夫斯特凡研究所的研究人员分析了用多种语言标注的情感推文的大数据集。
有趣的是,该项目的结果显示,顶级分类模型的性能没有显著的统计差异。相反,人类注释者的质量是决定模型准确性的更大因素。
为了评估他们的标注者,团队使用了标注者之间的识别和自我识别过程。研究发现,虽然自我识别是去除不良标注者的一种好方法,但标注者之间的识别可以用来衡量任务的客观难度。
研究论文:《多语言Twitter情绪分类:人类注释器的角色》(多语种推特情感分类:人类注释者的角色)
作者/供稿人:伊戈尔莫西迪奇、米哈格尔卡尔、亚斯米娜斯迈洛维奇(所有作者均来自乔泽夫斯特凡研究所)
发布/最后更新:2016年5月5日
2.机器学习的数据收集综述
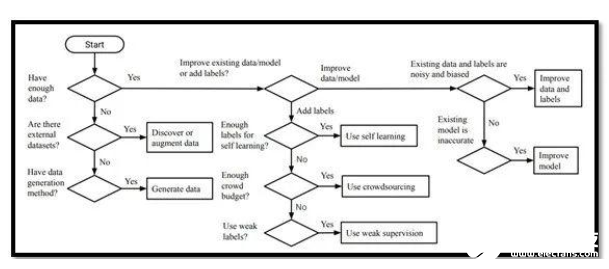
本文来自韩国高级科学技术研究所的一个研究团队,非常适合希望更好地了解数据收集、管理和注释的初学者。此外,本文还介绍和说明了数据采集、数据扩展和数据生成的过程。
对于那些对机器学习不熟悉的人来说,本文是一个很好的资源,它可以帮助你理解许多可以用来创建高质量数据集的常用技术。
研究论文:《机器学习的数据收集调查》(机器学习数据收集调查)
作者/供稿人:卢裕基、许真、史蒂文尤钟旺(所有作者均来自韩国科学技术研究所)
发布/最后更新:2019年8月12日
3.用于半监督学习和迁移学习的高级数据增强技术
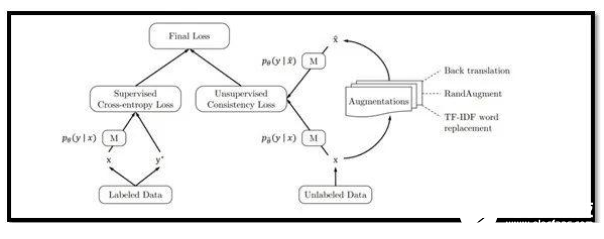
目前,数据科学家面临的最大问题之一是获取训练数据。也可以说,深度学习面临的最大问题之一是,大多数模型需要大量的标签数据来发挥高精度的作用。
为了解决这些问题,来自谷歌和卡内基梅隆大学的研究人员提出了一个框架来训练模型,同时大大减少数据量。该团队建议使用先进的数据增强方法来有效地为半监督学习模型中使用的未标记数据样本添加噪声。这个框架可以取得令人难以置信的结果。
该团队表示,在IMDB文本分类数据集上,他们的方法仅通过在20个标记样本上训练就能超越最先进的模型。此外,他们的方法在CIFAR-10基准测试中优于所有以前的方法。
标题:《用于一致性训练的无监督数据增强》(一致性培训的未保存数据补充)
作者/供稿人:谢启哲(1 1,2)、戴子航(1 1,2)、爱德华霍维(2)、明堂朗(1)、郭克诉勒(1)(1——谷歌研究院、谷歌大脑团队、2——卡内基梅隆大学)
发布日期/最后更新:2019年9月30日
4.利用监管不力标记大量数据
对于许多机器学习项目来说,获取和注释大型数据集需要很多时间。在这篇论文中,斯坦福大学的研究人员提出了一个通过“数据编程”过程自动创建数据集的系统。
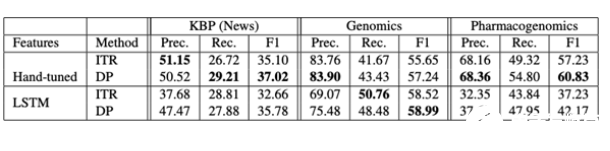
上表是从论文中直接提取的,并使用数据编程(DP)显示了与ITR远程监控方法相比的准确率、召回率和F1评分。
系统使用弱监督策略来标记数据子集。生成的标签和数据可能有一定程度的噪声。然而,该团队随后将训练过程表述为生成一个模型来消除数据中的噪声,并提出了一种方法来修改损失函数,以确保它是“噪声感知的”。
研究论文:《数据编程:快速创建大型训练集》(数据编程:快速创建大型训练集)
作者/撰稿人:亚历山大拉特纳、克里斯托弗德萨、森吴、丹尼尔萨姆、克里斯托弗雷(所有作者均来自斯坦福大学)
发布/最后更新:2017年1月8日
5.如何使用半监督知识转移来处理个人身份信息(PII)
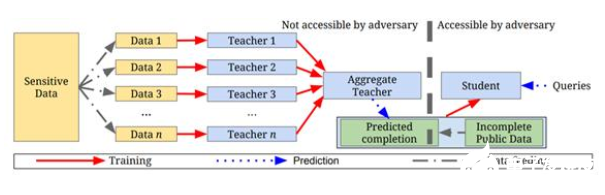
来自谷歌和宾夕法尼亚州立大学的研究人员介绍了一种处理敏感数据的方法,比如医疗记录和用户隐私信息。这种方法被称为教师集私有化(PATE),它可以应用于任何模型,并且可以在MNIST和SVHN数据集上实现最先进的隐私/效用折衷。
然而,正如数据科学家亚历杭德罗阿里斯蒂萨巴尔在文章中所说,百达翡丽设计的主要问题之一是,该框架要求学生模型和教师模型共享他们的数据。在这个过程中,隐私得不到保证。
阿里斯蒂萨巴尔提出了一个额外的步骤来加密学生模型的数据集。你可以在他的文章《让帕特比直接私人化》中读到这个过程,但是你必须先阅读他的原始研究论文。
论文题目:《从隐私训练数据进行深度学习的半监督式知识转移》(从私人培训数据进行深度学习的半监督知识转移)
作者/撰稿人:尼古拉斯帕佩诺特(宾夕法尼亚州立大学)、马丁阿巴迪(谷歌大脑)、伊尔法尔埃尔林森(谷歌)、伊恩古德菲勒(谷歌大脑)、库纳尔塔尔瓦(谷歌大脑)。
发布日期/最后更新:2017年3月3日
阅读顶级学术论文是了解学术前沿的唯一途径,也是从他人的实践中内化重要知识和学习优秀研究方法的好方法。阅读更多的论文肯定会对你有帮助。
-

-
无人车“入春”,批量上路仍需“爬坡”
防控疫情的需求激发之下,代替人类送药、送餐送菜、消毒巡逻的无人车成了疫情期间的特殊尖兵。疫情过后,无人车配送是否...
2020-03-23 17:12
-

-
5G、AI、大数据的发展,对智慧城市会有什么影响
市场分调研机构Omdia的最新数据分析显示,全球智能城市人工智能(AI)软件市场将从6 738亿美元(2019年),在2025年将增长到4...
2020-04-07 17:55
-

-
机器人制造过程中的传感器技术之磁光效应传感器
现代电测技术日趋成熟,由于具有精度高、便于微机相连实现自动实时处理等优点,已经广泛应用在电气量和非电气量的测量中。
2020-04-07 17:56
-

-
微软不需要快速拥抱VR
微软经常在游戏领域开辟路径,扮演开拓者的角色,这一点体现在很多方面,包括微软的尖端技术(DX12终极版 DX光追),硬件(X...
2020-04-07 17:57
-

-
波音Starliner载人航天器再次展开测试
去年 12 月,波音为美国宇航局发射了未载人的 Starliner 航天器。然而由于技术问题,任务并没有按计划进行。作为 NASA ...
2020-04-07 17:58