鲲云科技数据流技术实现新突破 更高算力性价比AI芯片CAI
2020年6月23日,鲲云科技在深圳举行产品发布会,发布全球首款数据流AI芯片CAISA,定位于高性能AI推理,已完成量产。鲲云通过自主研发的数据流技术在芯片实测算力上实现了技术突破,较同类产品在芯片利用率上提升了最高11.6倍。第三方测试数据显示仅用1/3的峰值算力,CAISA芯片可以实现英伟达T4最高3.91倍的实测性能。鲲云科技的定制数据流技术不依靠更大的芯片面积和制程工艺,通过数据流动控制计算顺序来提升实测性能,为用户提供了更高的算力性价比。
深圳市人民政府副市长、党组成员聂新平,福田区委副书记、区长黄伟,市科技创新委员会副主任钟海、市工信局副局长徐志斌、市科协党组成员、常务委员孙楠和福田区委常委、副区长舒毓民、原政协深圳市委员会副主席、党组成员、深圳市源创力离岸创新中心理事长王学为等政府领导及山东产业技术研究院副院长雷斌,深圳市源创力离岸创新中心总裁周路明,英特尔PSG中国区总经理、销售总监Tiffany Xia夏迎丽等合作伙伴出席发布会。聂新平、舒毓民同志分别为活动致辞。中国科协党组成员、书记处书记宋军,鲲云科技联合创始人兼首席科学家、英国皇家工程院院士、美国电子电气工程师学会(IEEE)会士、英国计算机学会(BCS)会士Wayne Luk陆永青院士,浪潮信息副总裁、浪潮AI & HPC总经理刘军,清华大学信息科学技术学院副院长、电子工程系主任、深鉴科技联合创始人汪玉教授,戴尔科技集团全球资深副总裁、大中华区企业解决方案总经理曹志平,鹏城实验室高级顾问、党委书记、清华大学计算机系教授、学位委员会主席、CCF会士杨士强,Intel Tiffany Xia夏迎丽,中国信息通信研究院云大所人工智能部主任、工信部人工智能技术和应用评测实验室常务副主任、中国人工智能产业发展联盟(AIIA)总体组组长、南京新一代人工智能研究院院长孙明俊等嘉宾为鲲云成功实现全球首款数据流AI芯片量产送上了祝福和寄语。
超高芯片利用率,定制数据流芯片架构完成3.0升级
此次发布的CAISA芯片采用鲲云自研的定制数据流芯片架构CAISA 3.0,相较于上一代芯片架构,CAISA3.0在架构效率和实测性能方面有了大幅的提升,并在算子支持上更加通用,支持绝大多数神经网络模型快速实现检测、分类和语义分割部署。CAISA3.0在多引擎支持上提供了4倍更高的并行度选择,架构的可拓展性大大提高,在AI芯片内,每一个CAISA都可以同时处理AI工作负载,进一步提升了CAISA架构的性能,在峰值算力提升6倍的同时保持了高达95.4%的芯片利用率,实测性能线性提升。同时新一代CAISA架构对编译器RainBuilder的支持更加友好,软硬件协作进一步优化,在系统级别上为用户提供更好的端到端性能。
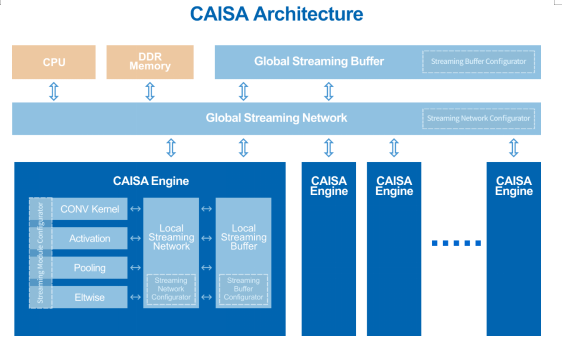
CAISA3.0架构图
CAISA3.0架构继续保持在数据流技术路线的全球领先地位,指令集架构采用冯诺依曼计算方式,通过指令执行次序控制计算顺序,并通过分离数据搬运与数据计算提供计算通用性。CAISA架构依托数据流流动次序控制计算次序,采用计算流和数据流重叠运行方式消除空闲计算单元,并采用动态配置方式保证对于人工智能算法的通用支持,突破指令集技术对于芯片算力的限制。此次升级,CAISA架构解决了数据流架构作为人工智能计算平台的三大核心挑战:
1. 高算力性价比:在保持计算正确前提下,通过不断压缩每个空闲时钟推高芯片实测性能以接近芯片物理极限,让芯片内的每个时钟、每个计算单元都在执行有效计算;
2.高架构通用性:在保证每个算法在CAISA上运行能够实现高芯片利用率的同时,CAISA3.0架构通用支持所有主流CNN算法;
3. 高软件易用性:通过专为CAISA定制的编译工具链实现算法端到端自动部署,用户无需底层数据流架构背景知识,简单两步即可实现算法迁移和部署,降低使用门槛。
具体来讲,鲲云CAISA3.0架构的三大技术突破主要通过以下的技术方式实现:
1. 高算力性价比:时钟级准确的计算
CAISA3.0架构由数据流来驱动计算过程,无指令操作,可以实现时钟级准确的计算,最大限度的减少硬件计算资源的空闲时间。CAISA3.0架构通过数据计算与数据流动的重叠,压缩计算资源的每一个空闲时钟;通过算力资源的动态平衡,消除流水线的性能瓶颈;通过数据流的时空映射,最大化复用芯片内的数据流带宽,减少对外部存储带宽的需求。上述设计使CNN算法的计算数据在CAISA3.0内可以实现不间断的持续运算,最高可实现95.4%的芯片利用率,在同等峰值算力条件下,可获得相对于GPU 3倍以上的实测算力,从而为用户提供更高的算力性价比。
2. 高架构通用性:流水线动态重组
CAISA3.0架构可以通过流水线动态重组实现对不同深度学习算法的高性能支持。通过CAISA架构层的数据流引擎、全局数据流网、全局数据流缓存,以及数据流引擎内部的人工智能算子模块、局部数据流网、局部数据流缓存的分层设计,在数据流配置器控制下,CAISA架构中的数据流连接关系和运行状态都可以被自动化动态配置,从而生成面向不同AI算法的高性能定制化流水线。在保证高性能的前提下,支持用户使用基于CAISA3.0架构的计算平台实现如目标检测、分类及语义分割等广泛的人工智能算法应用。
3. 高软件易用性:算法端到端自动化部署
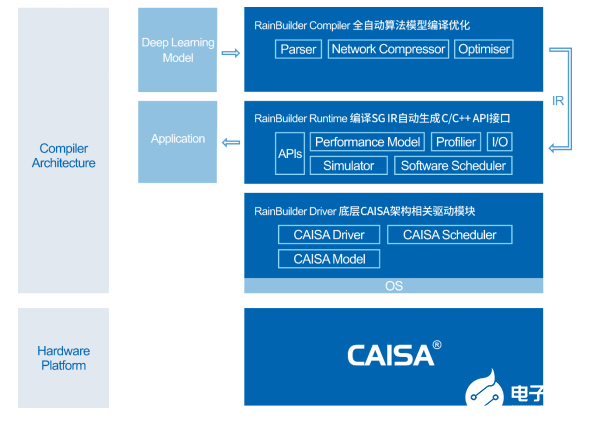
RainBuilder架构图
专为CAISA3.0架构配备的RainBuilder编译工具链支持从算法到芯片的端到端自动化部署,用户和开发者无需了解架构的底层硬件配置,简单两步即可实现算法快速迁移和部署。RainBuilder编译器可自动提取主流AI开发框架(TensorFlow,Caffe,Pytorch,ONNX等)中开发的深度学习算法的网络结构和参数信息,并面向CAISA结构进行优化;工具链中的运行时(RunTIme)和驱动(Driver)模块负责硬件管理并为用户提供标准的API接口,运行时可以基于精确的CAISA性能模型,实现算法向CAISA架构的自动化映射,同时提供可以被高级语言直接调用的API接口;最底层的驱动可以实现对用户透明的硬件控制。RainBuilder工具链使用简单,部署方便,通用性强,可以让用户快速和低成本的部署和迁移已有算法到CAISA硬件平台上。
首款量产数据流AI芯片,CAISA带来AI芯片研发新方向

CAISA芯片
作为全球首款采用数据流技术的AI芯片,CAISA搭载了四个CAISA 3.0引擎,具有超过1.6万个MAC(乘累加)单元,峰值性能可达10.9TOPs。该芯片采用28nm工艺,通过PCIe 3.0×4接口与主处理器通信,同时具有双DDR通道,可为每个CAISA引擎提供超过340Gbps的带宽。

CAISA芯片架构图
作为一款面向边缘和云端推理的人工智能芯片,CAISA可实现最高95.4%的芯片利用率,为客户提供更高的算力性价比。CAISA芯片具有良好的通用性,可支持所有常用AI算子,通过数据流网络中算子的不同配置和组合,CAISA芯片可支持绝大多数的CNN算法。针对CAISA芯片,鲲云提供RainBuilder 3.0工具链,可实现推理模型在芯片上的端到端部署,使软件工程师可以方便的完成CAISA芯片在AI应用系统中的集成。

鲲云科技创始人牛昕宇发布全球首款数据流AI芯片
高算力性价比的AI计算平台星空加速卡系列产品发布

星空加速卡系列产品图
发布会上,鲲云科技创始人和CEO牛昕宇博士还发布了基于CAISA芯片的星空系列边缘和数据中心计算平台,X3加速卡和X9加速卡,并公布了由人工智能产业技术联盟(AIIA)测试的包括ResNet-50, YOLO v3等在内的主流深度学习网络的实测性能。

星空X3加速卡发布
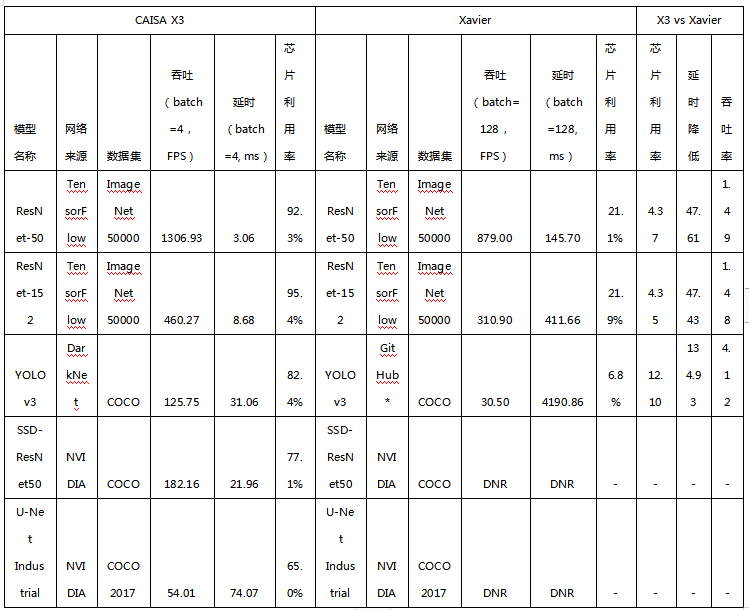
星空X3加速卡是搭载单颗CAISA 芯片的数据流架构深度学习推断计算平台,为工业级半高半长单槽规格的PCIe板卡。得益于其轻量化的规格特点,X3加速卡可以与不同类型的计算机设备进行适配,包括个人电脑、工业计算机、网络视频录像机、工作站、服务器等,满足边缘和高性能场景中的AI计算需求。相较于英伟达边缘端旗舰产品Xavier,X3可实现1.48-4.12倍的实测性能提升。
*模型参考:https://github.com/pushyami/yolov3-caffe/blob/master/deploy.prototxt
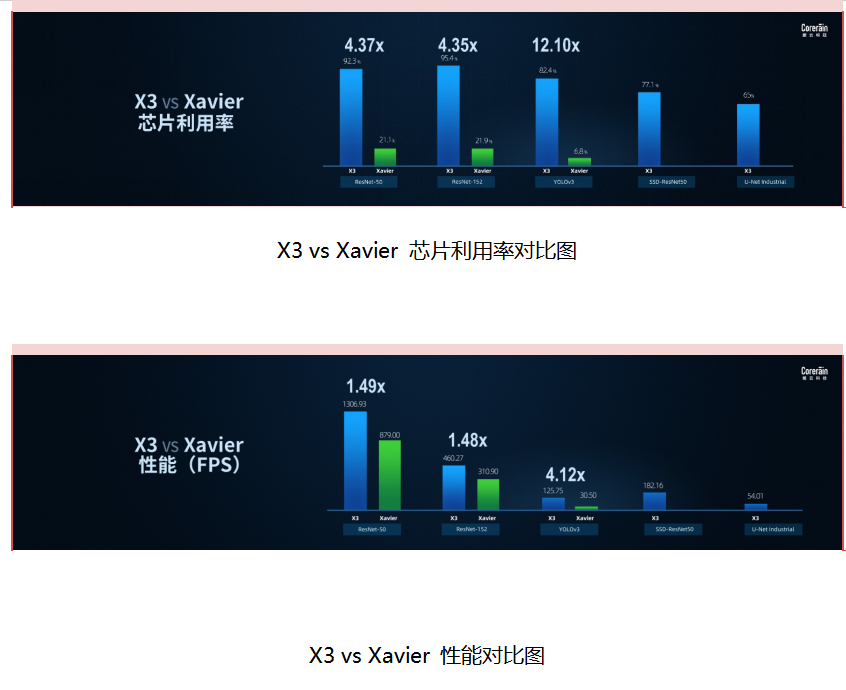

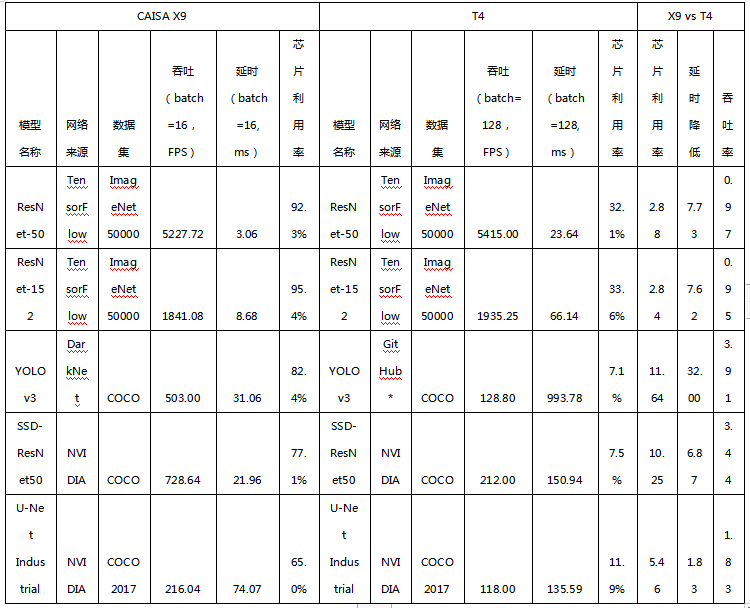
星空X9加速卡为搭载4颗CAISA 芯片的深度学习推断板卡,峰值性能43.6TOPS,主要满足高性能场景下的AI计算需求。同英伟达旗舰产品T4相对,X9在ResNet-50, YOLO v3等模型上的芯片利用率提升2.84-11.64倍。在实测性能方面,X9在ResNet50可达5240FPS,与T4性能接近,在YOLO v3、UNet Industrial等检测分割网络,实测性能相较T4有1.83-3.91倍性能提升。在达到最优实测性能下,X9处理延时相比于T4降低1.83-32倍。实测性能以及处理延时的大幅领先,让数据流架构为AI芯片的发展提供了提升峰值性能之外的另一条技术路线。
*模型参考:https://github.com/pushyami/yolov3-caffe/blob/master/deploy.prototxt
鲲云科技通过CAISA数据流架构提高芯片利用率,同样的实测性能,对芯片峰值算力的要求可大幅降低3-10倍,从而降低芯片的制造成本,为客户提供更高的算力性价比。目前星空X3加速卡已经实现量产,星空X9加速卡将于今年8月推出市场。鲲云科技成为国内首家在发布会现场披露Benchmark的AI芯片公司。
商业落地先行,鲲云加速卡实现多领域规模落地
作为技术驱动的AI芯片公司,鲲云科技自成立以来一直注重商业落地,目前鲲云科技已与多家行业巨头达成战略合作,成为英特尔全球旗舰FPGA合作伙伴,在技术培训、营销推广以及应用部署等方面进行合作;与浪潮、戴尔达成战略签约,在AI计算加速方面开展深入合作;与山东产业技术研究院共建山东产研鲲云人工智能研究院,推进人工智能芯片及应用技术的规模化落地。明星产品“星空”加速卡已在电力、教育、航空航天、智能制造、智慧城市等领域落地。自2016年成立至今,鲲云科技已经完成了天使轮,Pre-A轮及A轮融资,设有深圳、山东、伦敦研发中心。2018年成立人工智能创新应用研究院,定位于建立人工智能产业化技术平台,支持人工智能最新技术在各垂直领域快速实际落地,启动鲲云高校计划,开展人工智能课程培训和科研合作。除与Intel合作进行人工智能课程培训外,鲲云人工智能应用创新研究院已同帝国理工学院、哈尔滨工业大学、北京航空航天大学、天津大学、香港城市大学等成立联合实验室,在定制计算、AI芯片安全、工业智能等领域开展前沿研究合作。
-

-
设计紧凑轻巧的高功率和高频片式负载
密斯英特康,今日宣布推出最新CTX高频可引线接合片式负载系列。该系列经优化可在小封装体积中集成高频和高功率性能。
2020-04-08 09:26
-

-
英特尔推出NUC 8 Rugged,可在0°C到40°C的环境下运行
英特尔 NUC 8 Rugged 采用无移动部件的独特设计,能够日夜不停地连续可靠运行。
2020-04-08 09:28
-

-
不止有尊享权益,华为帐号全面开启你的P40系列超凡体验
" >
2020-04-09 15:03
-

-
关注算法安全新兴领域,清华团队RealAI推出业界首个AI模
" >
2020-04-09 15:03
-
-
新鲜资讯智慧直达!华为终端云服务为P40系列带来全场景内
" >
2020-04-09 15:05